A Eulogy for DevOps
DevOps, introduced in 2007 to improve development and operations collaboration, faced challenges like centralized risks and communication issues. Despite advancements like container adoption, obstacles remain in managing complex infrastructures.
Read original article
DevOps, a once revolutionary concept introduced in 2007 to bridge the gap between development and operations teams, has faced challenges leading to its decline. The initial vision of seamless software deployment and increased efficiency gave way to centralized risks and delays in practice. Organizations struggled with communication and coordination issues more than technical barriers. DevOps aimed to streamline processes, but the reality was labor-intensive and slow, hindering rapid feature releases. The shift to DevOps was partly driven by recruitment difficulties, sales pressures, and the rise of cloud platforms. The model emphasized speed over meticulous testing, with developers deploying changes directly to production. However, issues arose with server configuration discrepancies, unclear responsibilities, and operational complexities. The adoption of containers provided a boost to DevOps by enhancing consistency and simplifying server management. Despite advancements, challenges persisted in effectively operating and maintaining systems. DevOps evolved to prioritize continuous deployment but faced ongoing obstacles in managing and troubleshooting complex infrastructures.
 38 comments
38 commentsIt really cuts to the heart of it when you looking at the “devops cycle” diagram with “build, test, deploy” …and yeah, those other ones…
I remember being in a meeting where our engineering lead was explaining our “devops transformation strategy”.
From memory that diagram turned up in the slides with a circle on “deploy”; the operational goal was “deploy multiple times a day”.
It was about speed at any cost, not about engineering excellence.
Fired the ops team. Restructured QA. You build it you run it”. Every team has an on call roster now. Sec dev ml ops; you’re an expert at everything right?
The funny thing is you can take a mostly working stable system and make fast thoughtless chaotic changes to it for short term gains; so it superficially looks like it’s effective for a while.
…but, surrrrpriiiisssseeee a few months later and suddenly you can’t make any changes without breaking things, no one knows what’s going on.
I’m left with such mixed feelings; at the end of the day the tooling we got out of devops was really valuable.
…but it was certainly a frustrating and expensive way to get there.
We have new developers now who don’t know what devops is, but they know what containers are and expect to be able to deploy to production any time.
I guess that’s a good way for devops to quietly wind up and go away.
My first experiences had to do with the ability to add new services, monolith or not, and have their infrastructure be created/modified/removed in a environment/region in-specific way, and to be able to safely allow developers to self-service deploy as often as they want, with the expectation that there would be metrics available to observe the roll-out, and safely revert without manual intervention.
If you can't do this stuff, then you can't have a serious posture on financial cost, while also providing redundancy, security, or operating independently of one cloud provider, or one specific region/datacenter. Not without a lot of old school, manual, systems administrator work. DevOps hasn't gone away, it has become the standard.
A bunch of pet servers is not going to pass the appropriate audits.
I think a lot of Kubernetes hate is misplaced. It is a great piece of software engineering, well supported and runs everywhere. You certainly don't always need it but don't create a bunch of random bash scripts running all of the place instead of learning how to use it.
So many arguments are based on strawmen...
I like devops / daily deploys, because they're part of the puzzle leading to higher quality code being deployed on production, and associated less stress.
The point is (for any individual developer) not to actually deploy their progress every day on prod, but to have the option to do so. This leads to code going on prod when it's ready, but no sooner. If the problem is more difficult than anticipated, code still sucks and needs refactoring, well, you're just going to work on it as long as it needs it and deploy it only then.
Meanwhile if you have let's say monthly releases, you will get the death marches, because delay of one day can mean delay of one month / quarter / whatever. Everyone feels the pressure to deliver, leading to suboptimal choices, bad code being approved etc.
As startups grow into enterprises, eventually there are benefits to be had from getting all the different SREs on the same page and working according to the same standard (e.g. compliance, security, FinOps...). Then, instead of each SRE building on top of the cloud provider directly, each SRE builds on top of the internal platform instead.
Hiring an entire team to build great dev-tooling and deployments, monitoring, application templates, org level dependency management etc is just too much to swallow for any medium sized or smaller business, so in that reality you wind up with a few heavily overworked devops folks who take up unhealthy habits to cope with the associated stress and risk.
In my 10 year career thus far none of the startups I worked for, even well capitalized ones had what this article, and myself, would consider to be a platform team. I only saw my first platform team when I stepped into a role at 6000+ person company.
It's effectively an underserved (and under-appreciated imo) area and responsible for a lot of pain and land-mine decisions companies make around their software product.
If you can afford to make the user the tester, you should. There is no moral hazard, only an economic one. If you have 5 million customers paying $1 / year, make the user do the testing via canary deployments, metrics, etc. If you have 5 customers each paying $1M / year, be sure to test it yourself.
The problem seems to be that people forget which regime they are operating in.
For leadership, the whole idea of "breaking down silos" is almost always lip-service, and to the extent that is/was a core mission of DevOps, it was always doomed. Responsibility without power doesn't work, so it's pointless unless the very top wants to see it happen. Strong CTOs with vision are pretty rare, and the reality is that the next tier of department heads from QA/Engineering/DataScience/Product are very often rivals for budgets and attention.
People that get to this level of management usually love building kingdoms, and see most things as zero-sum, so they are careful to never appear actually uncooperative but they also don't really want collaboration. Collaboration effectively increases accountability and spreads out power. If you're in the business of breaking down silos, almost everyone will be trying undermine you as soon as they think you're threatening them with any kind of oversight, regardless of how badly they know that they need process changes.
Anyway, the best devops people are usually excited to code themselves out of a job. To a large extent.. that's what has happened. We're out of the research phase of looking for approaches that work. For any specific problem in this domain we've mostly got tools that work well and scale well. The tools are documented, mature, and most even permit for a healthy choice amongst alternatives. The landscape of this tooling is generally hospitable, not what you'd call a desert or a jungle, and it's not as much of a moving target to learn the tech involved as it used to be.
Not saying every dev needs to be a Kubernetes admin.. but a dev refusing to learn anything about kubernetes in 2024 is starting to look more like a developer that doesn't know Linux command line basics. Beyond the basics, Platform teams are fine.. they are just the subset of people with previous DevOps titles that can actually write code, further weeding out the old-school DBAs / Sysadmins, bolstered by a few even stronger coders that are good with cloud APIs but don't understand ELBs / VPCs.
It doesn't mean CI/CD pipelines, Terraform, or YAML. Those are all incidental.
The moment specialised "DevOps" teams started springing up it was all over. We just reinvented the sysadmin.
1. I feel that one big and important aspect of devops that isn’t mentioned is that smaller releases are less likely to have killer bugs. If you can release one change a day rather than 100 changes a quarter then overall I think there’s a strong argument, not to be had here, that you’ll have faster releases and less bugs overall, assuming my next point. This doesn’t take away from the article, but it’s just something I don’t see discussed much.
2. I think a huge part of the problem is that business management keeps trying to abstract away engineering management. The most productive team I’ve ever been part of was when I was able to spend most of my time planning and coordinating the work, as part of an overall vision, while my peers did the implementation and gave me feedback. One side effect of this was that productivity was actually measurable. But the value of productivity is lost on business management who saw me as just engineer - one who had the authority, furthermore, to push back against stupidity and was therefore a pain in the ass. Technical management is not valued, because it’s not understood, and this is seen in the endless cycle of fads designed to make all engineers fungible.
I really enjoy working in a deploy often and fast environment though and I firmly believe that fast feedback loops are one of the most important things for development speed. And this is what DevOps at its heart is about. How you achieve this and how reasonable it is for your situation is left for you to decide.
But every single idea I read in that post is just wrong. Like author never worked in siloed team where you had to wait blocked for a week so DBA guy picks up your change request. Then if something went wrong on prod you had to wait for SysAdmin to basically be your typist because you did not have access right.
It is not that you don’t need DBA or SysAdmin but for devops purpose they are assigned to a team - which makes companies needing more of those people NOT LESS - because earlier you had single DBA to know all of company projects which was cheaper for business. Now idea is you have people in the teams so you don’t throw stuff over the wall but single team can deploy and operate their project with full knowledge.
Well of course there are companies that take 5 jr devs and now assign them to be devops team but that is company work organization problem not devops problem.
So that even if you're building small website for your local soccer club it's probably run through GHA on every change with a full red/green deploy process, run on autoscaling groups and so on.
Never mind that most of these applications' databases could fit into RAM on a single server with 24 cores and never even touch the system limits.
Where devops went wrong in a lot of teams though is assuming it's a full time role for a specialist that then does your devops. That's not devops. It's ops. And these aren't developers but operations people. Embedding them in teams is still progress though as it removes obstacles.
But if you do it right, this is not a full time thing at all. The wrong way is generating a lot of busywork for your devops people to develop loads of yaml files that feed into things like Kubernetes, Terraform and then enable organizations to codify their structure into their deployment architecture using microservices (Conway's law). I'd suggest not doing that and doing things that minimize the need for devops people. Like using monoliths.
I prefer solutions that minimize my time involvement. I use monoliths so I don't have to babysit a gazillion deployment scripts. I need just one of those. And since I don't have micro services, I use docker compose, not Kubernetes. The deployment script is just a few lines of bash that restarts docker compose. It kicks in with a simple Github action. The amount of time setting that up is a few hours at best. I rarely need to touch those files. We have no Terraform because our production environment got created manually and we're not in the habit of destroying and recreating that a lot since we launched it years ago. And it's simple enough that I can click a new one together in an hour or so. Automating one off things like that has very low value to me.
- the application has hardcoded paths.
- the service discovery isn’t dynamic
- the branching strategy doesn’t account for edge cases.
- the build process doesn’t account for edge cases.
- and many other things that are related to bad practices.
I recall an old boss saying he wanted stable dev environments which sounded an oximoron. I’ve always aimed to have an environment where I can reproduce a desired behavior wether is a faulty or not.
Jesus this. No one knows where the money goes. If you can't tell me cost per customer, per user then your business is missing key metrics.
> ... "discovered" that troubleshooting Kubernetes was a bit like Warhammer 40k Adeptus Mechanicus waving incense in front of machines they didn't understand in the hopes that it would make the problem go away.
Wackamole with problems...
The part where he talks about the death of QA.. yea. This is enshitifcation in action.
It doesn't scale very well: the larger the codebase/team, the more burden on each individual to make this work.
I used to have passwords for everything and could deploy things and get things done on a dime, now there are layers of bureaucracy and middle fingers everywhere I turn.
Is that DevOps?
Having been a frontend guy some 10+ years ago, into a network engineer, then infrastructure engineering and now SRE. The amount of people on both sides of the developer circle and operations circle that do not want to understand what's going on is mind boggling.
I was around when VMs were hot, when treating them as long living pets was just toil that operations dealt with. The collection of shell scripts to make that toil go away was nice. Then puppet, ansible and the like.
Now we are in the golden ages of Kubernetes and orchestration platforms. We have a set of standards for how things can be operated. The terms are obfuscated sure, but the core concepts are still the same underneath the abstraction.
I agree that platform engineering is a good place to be, and honestly it needs to be understood more by all parties including executives. They were bought and sold cloud on the idea that it's all managed, but that cannot be further from the truth, wrinkles will show as scale grows and your use cases progress in any environment, at home or in the cloud.
Unfortunately good platform teams often aren't seen. A good platform just works, metrics just exist, logs just work, tracing just works out of the box. Things don't often go down. It's really only visible when things fail. If you do a great job implementing a self service platform you're often met with executives wondering why you're there because the cloud does it all!
Applications are highly visible to all, but so are the layers underneath and they all work together if done correctly, I wish that was more understood.
For context, I'm currently running multiple environments of Kubernetes, on premise and in cloud. Our team prides itself on using open source solutions utilizing the operator model. Prometheus, Thanos, Loki, Tempo, Istio, Cert-Manager, Strimzi Kafka, Flink operator, Otel collector etc. We do billions of requests a month and TBs of bandwidth with microservices. Have at a minimum 4 9's of uptime, and our cost footprint is extremely small. This comes from a 4 man platform team that also handles on call for all applications, security, cloud budget, and operations. It's not impossible.
I guess I can't emphasize enough that understanding what the orchestration systems, the tooling and the stack are trying to do makes everything easier. As a developer you can understand your constraints and limitations. You can build off of known barriers. As an operations or platform engineer you can build things that don't require constant babysitting or toil.. you can save hundreds of thousands of dollars not offloading your observability to data dog or the like, you can make an impact. The technology is already here.
K8s is a complex tech that requires multidisciplinary experience that small and medium orgs cannot afford. Even if they could, there simply is not enough talent to hire. My own experience shows that k8s makes developers less productive, because running a heavy stack locally is not exactly conducive to fast development cycles. I don't feel empowered, I feel abandoned and left dealing with a steaming pile of shite that used to be the responsibility of a DBA, Ops, and security. Unfortunately, the trend for hiring "full stack developers" who can do frontend, backend, infra, and DBA aka. "I want a whole team for the price of a junior dev" is not going away.
This guy and the person that quit the bullshit industrial complex 6 months ago should get together and launch a startup.
Better yet, we should all go and join Jeremy Howard's answer.ai pro bono. Besides being miraculously headed by a guy who is Not An Asshole, it incidentally also had the most refreshing launch post (in the warm and fuzzy way) this side of the AI bubble.
The launch post concluded with this heading:We Don’t Really Know What We’re Doing.[0]
I mean, for the finest minds in our respective fields, what else is there left to say really?
No joke, containers are amazing, regardless of how quickly you try to move or how often you need to deploy.
I remember a project where the performance turned out to be horrible because someone was running Oracle JDK 8 instead of OpenJDK 8 and that was enough to result in a huge discrepancy, here's an example of the request processing times during load tests: https://blog.kronis.dev/images/j/d/k/-/t/jdk-testing-compari...
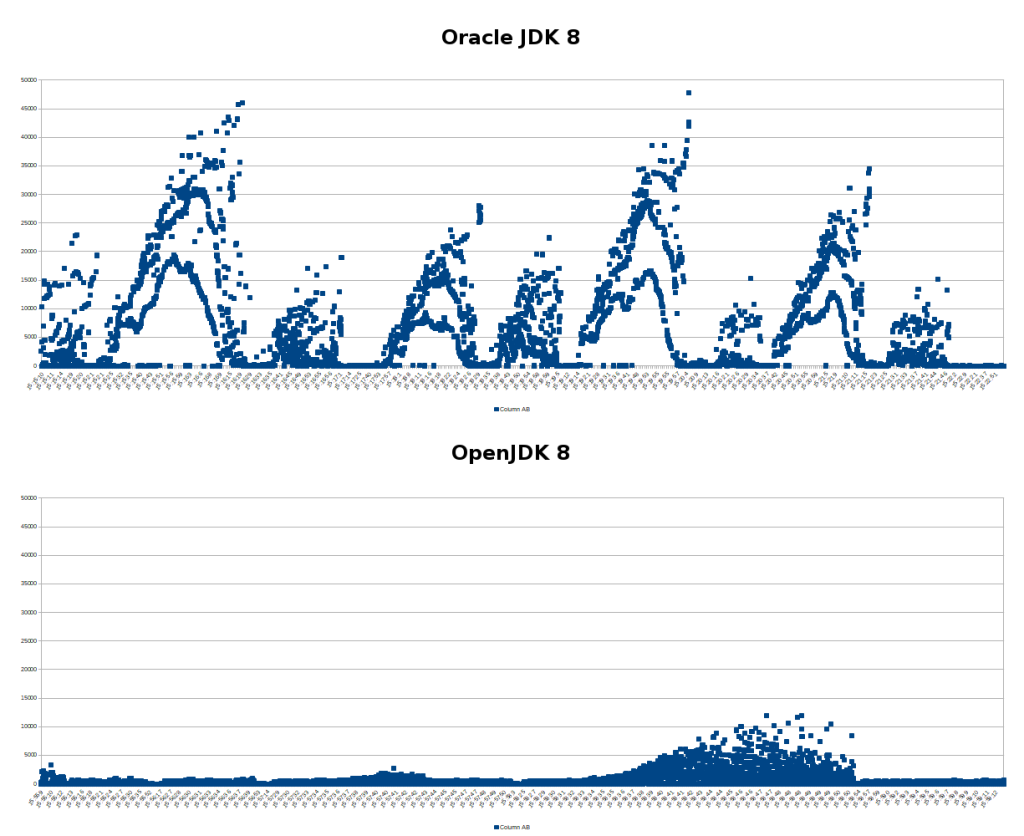{kind=link}
That would have been solved by Ansible or something like it, of course, but containers get rid of that risk altogether, since you need to package the JDK your app needs (and that it will be tested on).
With a bit of work, using containers can be quite consistent and manageable - have Ansible or something similar set up your nodes that will run the containers, run a Docker Swarm, Hashicorp Nomad or Kubernetes cluster (K3s is great) that's more or less vanilla, something like Portainer or Rancher for easier management, Skywalking or one of those OpenTelemetry solutions for tracing and observability, throw in some uptime monitoring tools like Uptime Kuma, maybe even something like Zabbix or a more modern alternative for node monitoring and alerting and you're set. Anything that's self-hostable and doesn't tie you up with restrictive licenses (this also applies to using PostgreSQL or MariaDB instead of something like Oracle, if you can).
You don't need to have every team branch out into completely different tools because those are the new hotness, you don't need to run everything on PaaS/SaaS platforms when IaaS is enough, realistically most of what you need can be stored in a Git repo that will contain a pretty clear history of why things have been changed and even some Wiki pages and/or ADRs that explain how you've gotten here.
The situations in the article feel very much like corporate not caring and teams not talking to one another and having no coordination, or growing to a scale where direct communication no longer works yet not having anything in place to address that. If you're at that point, you should be able to throw money and human-years of work at the problem until it disappears, provided that people who hold the bag actually care.
For what it's worth, regardless of the tech you use or the scale you're at, you can still have someone in charge of the platform (or a team, where applicable), you can still have a DBA or a sysadmin, if you recognize their skills as important and needed.